Disclosure: HappyHorse 1.0 is an unreleased model. No weights, no API, no official team announcement as of April 8, 2026. This article analyzes publicly reported architectural claims, benchmark fingerprints, and circumstantial evidence. GoIMG is not affiliated with the HappyHorse team.
Why This Model Matters
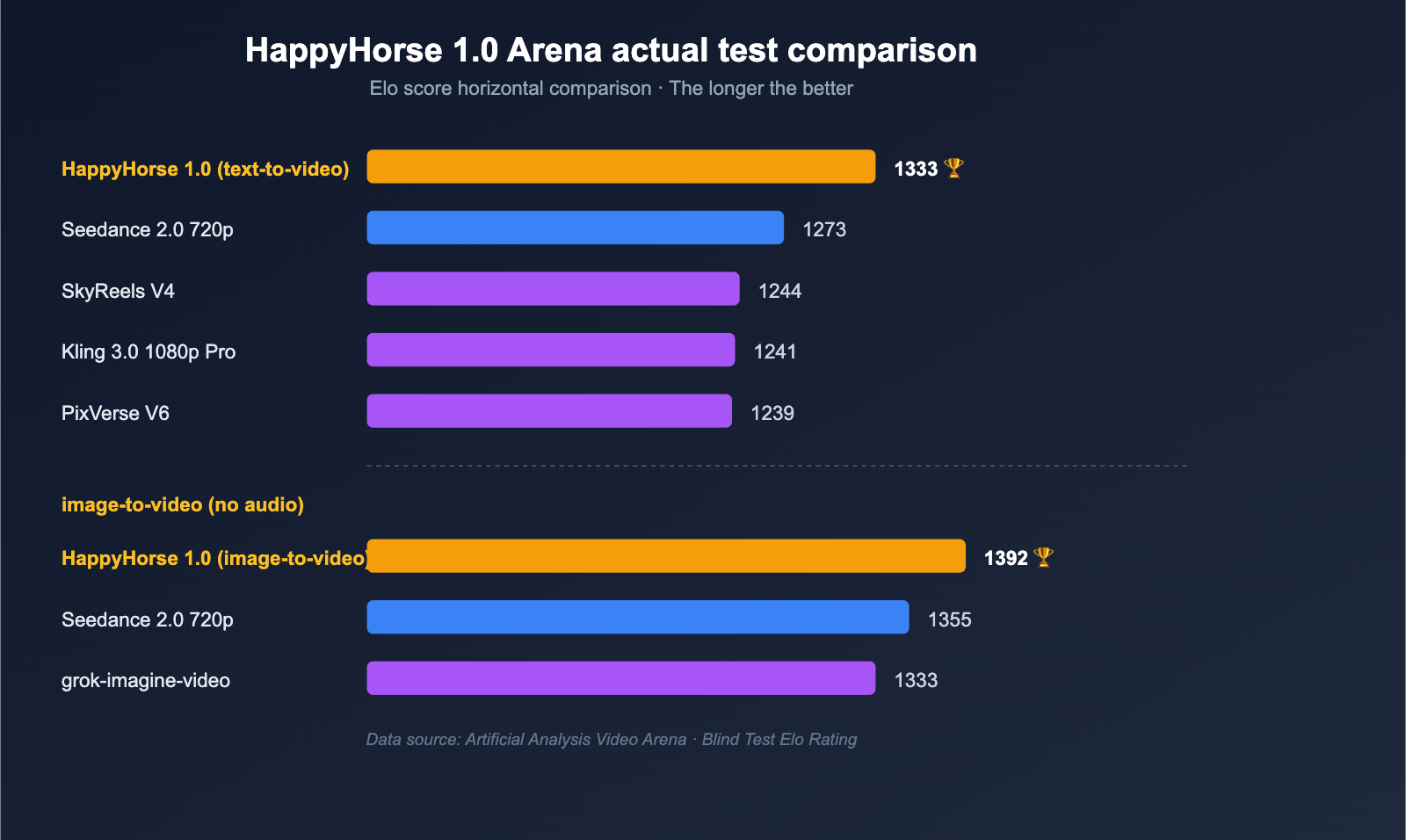
On April 7, 2026, the AI video research community had a strange day. A model nobody had heard of — HappyHorse-1.0 — appeared in the Artificial Analysis Video Arena blind-test leaderboard at an Elo of approximately 1333, ahead of Seedance 2.0, Kling 3.0, PixVerse V6, and several closed-source frontier models.
Then, within roughly 48 hours, it was gone.
What's interesting about HappyHorse isn't just that it topped the leaderboard. It's how — and what its architectural fingerprint suggests about who might have built it. This article walks through what the public information actually reveals: the architecture, the benchmark numbers, the inference design, and the trail of clues pointing to a probable lab of origin.
The Architecture, As Reported
Public-facing material from the brief HappyHorse landing pages described a fairly specific model design.
| Component | Reported Specification |
|---|---|
| Backbone | Single-stream Transformer |
| Layers | 40 |
| Parameters | ~15 billion |
| Modalities | Text → video, image → video, joint audio + video |
| Native resolution | 1080p |
| Audio coverage | 7 languages, claimed "ultra-low WER" lip-sync |
| Distillation | DMD-2 (Distribution Matching Distillation, v2) |
| Denoising steps | 8 |
| Inference time | ~38 seconds per 1080p clip (claimed) |
| License | "Fully open source, commercial use" (claimed; no weights released) |
Several things stand out.
The "Single-Stream" Design
In recent AI video models, modalities (video frame patches, audio waveforms, text embeddings) typically flow through separate pathways that are then fused — either via cross-attention layers or through a shared latent bottleneck. This is computationally efficient and easier to train, but it limits how tightly the modalities can be entangled.
A single-stream architecture, by contrast, runs all modalities through the same self-attention pathway. Tokens are interleaved — a video frame patch sits next to an audio spectrogram chunk sits next to a text caption token, all participating in the same attention operation.
The trade-off is well-known:
- Pro: tighter cross-modal alignment (lip-sync, audio-driven motion, text-frame coherence)
- Con: quadratic attention costs scale brutally with token count
- Con: training instability without careful curriculum design
If HappyHorse really uses a 40-layer single-stream design at ~15B parameters and produces native 1080p with synced audio in 8 denoising steps, that's an aggressive engineering claim — exactly the sort of thing you'd expect from a lab that has invested heavily in attention optimization (Flash Attention 3, custom Triton kernels, sequence parallelism).
DMD-2 Distillation and 8 Steps
The original Distribution Matching Distillation (DMD) showed that diffusion models can be distilled into much faster generators while preserving most of the output quality. DMD-2 is a refinement that addresses some training stability issues.
8 denoising steps for a 1080p video is fast — significantly faster than typical 25-50 step diffusion sampling. This matches up with the claimed ~38-second inference time and suggests the team prioritized real-world deployability over benchmark-only performance.
This is also a clue. Labs that ship distillation aggressively tend to be labs that are planning to deploy at scale, not academic groups publishing for prestige.
The Benchmark Performance
In Artificial Analysis Arena blind voting:
| Model | Approximate Elo |
|---|---|
| HappyHorse-1.0 | ~1333 |
| Seedance 2.0 | (below HappyHorse) |
| Kling 3.0 | (below HappyHorse) |
| PixVerse V6 | (below HappyHorse) |
Both V1 and V2 of HappyHorse simultaneously climbed the Text-to-Video and Image-to-Video charts — meaning whatever architecture the team built, it generalized cleanly across input modalities.
A few things to note about the benchmark itself:
- Arena Elo is preference voting, not feature parity. It tells you which output a human voter prefers in a blind side-by-side comparison. It does not directly measure prompt adherence, motion physics, or reference accuracy.
- HappyHorse vanished before independent reproduction. The Elo number we have is a snapshot, not a verified result.
- Other reported metrics (visual quality 4.80, alignment 4.18, consistency 4.52 on a 5-point scale) match a different model name internally referenced as daVinci-MagiHuman. This is part of the trail.
The "Who Built This?" Trail
This is where it gets interesting.
Clue 1: Language Ordering
The brief HappyHorse landing pages listed Mandarin and Cantonese ahead of English in their language selectors. This is a small but specific tell — Western teams almost universally put English first, even when they support Chinese. Chinese teams shipping internationally often default to Mandarin first.
Clue 2: Benchmark Fingerprints Match daVinci-MagiHuman
Internal benchmark numbers reported for HappyHorse on visual quality, alignment, and consistency closely match a model previously associated with the name daVinci-MagiHuman — a name that has surfaced in research blog posts tied to Sand.ai and the Shanghai Innovation Institute collaboration.
Clue 3: The "Disappear and Pretend Nothing Happened" Pattern
Stealth releases that appear on a leaderboard, dominate, then vanish without official acknowledgment are a known pattern from labs that want to measure themselves against the field without committing to a public launch timeline — essentially using public benchmarks as free QA. Several large Chinese AI labs have used this exact pattern in image generation in 2025 and 2026.
The Best Guess
None of this is proof. But the most parsimonious explanation, given the evidence:
HappyHorse-1.0 is most likely a stealth Arena entry from a Chinese AI lab — plausibly Sand.ai in collaboration with the Shanghai Innovation Institute — testing the daVinci-MagiHuman lineage against Western models before deciding on a public release strategy.
This is a guess, not a fact. We will update this article if HappyHorse releases officially or if a different lab claims it.
What This Tells Us About AI Video in 2026
Even if HappyHorse never ships properly, the episode reveals something useful about the state of AI video generation right now:
- The frontier is no longer dominated by US labs. Chinese teams (ByteDance with Seedance, Kuaishou with Kling, Sand.ai/Shanghai Innovation Institute with whatever HappyHorse turns out to be) are shipping models that meet or beat Western alternatives on blind preference voting.
- Single-stream multimodal designs are getting practical. The compute cost has historically been the blocker. If HappyHorse's claimed 8-step distillation actually works at 1080p, that's a meaningful optimization breakthrough, regardless of who built it.
- Distillation is now table-stakes for production AI video. Models that aren't distilled to under 10 sampling steps simply won't compete on inference cost. HappyHorse's design is consistent with this — Seedance 2.0 is also production-optimized along similar lines.
- The leaderboard wars are getting weird. Stealth submissions, vanishing entries, mystery teams — this is what happens when public benchmarks become the primary marketing channel for AI labs. Expect more of this, not less.
What Should You Actually Do With This Information?
If you're a researcher: watch the model card hosting sites (Hugging Face, GitHub, ModelScope) for any HappyHorse release. The architectural claims are interesting enough to be worth studying if and when weights drop.
If you're a builder shipping a product: keep building on what exists. Vaporware models don't make videos. Seedance 2.0 remains the most capable production AI video model with documented features, and it's available right now via the Happy Horse video generator on GoIMG — text-to-video, image-to-video, native audio, multi-shot output, and cinematic camera control all in one place.
If you're a competitive intelligence person: the HappyHorse incident is the clearest signal yet that the next generation of AI video models will likely be released stealthily, distilled aggressively for inference cost, and benchmarked against frontier Western models from day one. Plan accordingly.
Related Reading
- 📰 HappyHorse 1.0: The Mystery AI Video Model That Topped the Arena and Vanished — the news story
- ⚔️ HappyHorse 1.0 vs Seedance 2.0: Which AI Video Generator Is Actually #1? — head-to-head comparison
- 🎬 Seedance 2.0: The Future of AI Video Generation — what's actually shipping today