Disclosure: GPT-Image-2 was announced by OpenAI on April 16, 2026. At the time of writing, broad API access is still rolling out and independent benchmarks are limited. This article reflects what we know from the announcement and early community reports. GoIMG is not affiliated with OpenAI.
A Real Launch, Not a Mystery Model
Late on April 16, 2026, OpenAI announced GPT-Image-2 — the successor to GPT-Image-1, the native image generation capability that shipped inside GPT-4o a little over a year ago.
Unlike the recent HappyHorse-1.0 arena incident, where a mystery model topped a leaderboard and vanished, this one is the real thing: a named launch from a known lab, backed by documentation, with a phased rollout across ChatGPT, the OpenAI API, and the Images playground.
If you want to skip ahead and just make images in the meantime, GoIMG's GPT-Image-2 page runs on ByteDance's Seedream 5.0 and is available right now.
What GPT-Image-2 Is
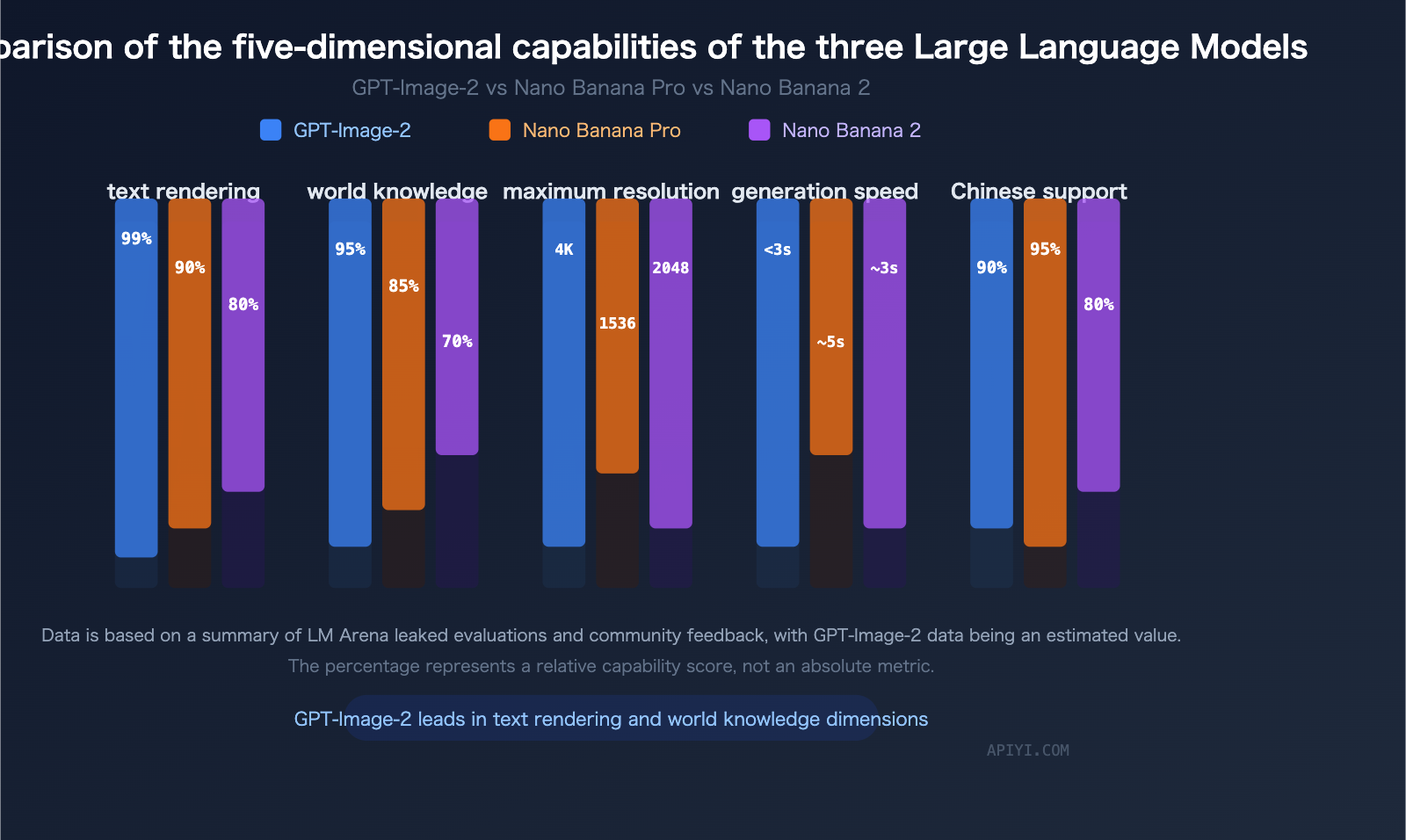
At its core, GPT-Image-2 is a native image generation model — meaning images are not produced by a separate diffusion pipeline bolted onto a text model, but generated directly by the same multimodal transformer stack that handles text. This is the same design philosophy that made GPT-Image-1 stand out: by letting the language model speak directly in image tokens, you get much tighter text-in-image rendering, world-knowledge grounding, and instruction following.
GPT-Image-2 keeps that architecture and pushes on every axis:
- Sharper outputs — higher effective resolution without quality loss
- Better text rendering — a historical strength of the GPT-Image lineage, now more reliable at small sizes and across languages
- More faithful instruction following — multi-element prompts with specific spatial or stylistic constraints behave the way GPT-style users expect
- Stronger reference/edit behavior — composable edits across a set of input images, not just single-image transforms
- Faster and cheaper at every resolution tier, per OpenAI's guidance
OpenAI's positioning is that GPT-Image-2 is the model that finally makes "an image generator that just does what you say" feel unambiguously true.
What Actually Changed vs GPT-Image-1
Three things stand out.
1. Reasoning Meets Image Generation
The biggest architectural shift isn't a new sampler or a diffusion trick — it's that the same reasoning machinery that powers the o-series and GPT-4.x can now think before emitting image tokens. In practice:
- Complex prompts with several simultaneous constraints (brand colors, specific typography, compositional rules) get resolved coherently rather than averaged
- Instructions like "the label should read exactly 'Artisan Sourdough' in a 1920s-style script, placed bottom-center, and the loaf should have four diagonal scoring marks" actually produce exactly that
- Edits become conversational — you can describe the transformation you want and GPT-Image-2 interprets it in context instead of blind-filling a mask
2. Text Is Effectively a Solved Problem
Text rendering has been the single most consistent failure mode of the diffusion era. GPT-Image-2 closes this gap almost entirely for Latin scripts and dramatically improves CJK (Chinese, Japanese, Korean), Arabic, and Cyrillic. Headlines, captions, poster layouts, product labels, and multi-line typographic layouts now ship usable on the first generation in most cases.
3. Composable Edit Semantics
GPT-Image-2 treats reference images as first-class inputs rather than as style hints. Pass in a character sheet and a scene; get the character in that scene with consistent facial identity, clothing, and accessories. Pass a before/after edit pair; get the same transformation applied to a third image. Pass a color palette as a reference; get it respected across a full campaign.
This is the feature that matters most for production work.
What GPT-Image-2 Does Not Change
Two realities deserve honest framing.
It is still a cloud-only model. No weights, no local inference, no self-hosting. For many creators that is fine; for researchers and teams with data-residency constraints it is not.
Broad API access is phased. As of the announcement, GPT-Image-2 is live in ChatGPT for Pro subscribers and rolling out to the OpenAI Images API in waves. Expect rate limits, access gates, and periods of capacity-limited availability over the first few weeks. This is standard OpenAI launch practice.
What to Do Right Now
If you already have access: start A/B testing GPT-Image-2 against whatever you were shipping before. The text rendering and instruction-following improvements are real and worth integrating into any pipeline that generates marketing, product, or editorial imagery.
If you don't yet have API access, or you need to ship today, the closest production-ready alternative is Seedream 5.0. It matches GPT-Image-2 on many of the same axes that matter in practice:
- Up to 3K native output
- Strong text rendering, including non-Latin scripts
- Deep reasoning for multi-constraint prompts
- Web-connected retrieval for current-events accuracy (something GPT-Image-2 does not explicitly advertise)
- Available right now via the GPT-Image-2 page on GoIMG
Want the Deeper Dives?
- ⚔️ GPT-Image-2 vs Seedream 5.0: Which AI Image Model Should You Actually Use? — head-to-head feature comparison
- 🧠 Inside GPT-Image-2: How OpenAI's Native Image Model Likely Works — technical analysis